RAG Systems: Beyond Basic Implementation!
RAG Systems: Beyond Basic Implementation

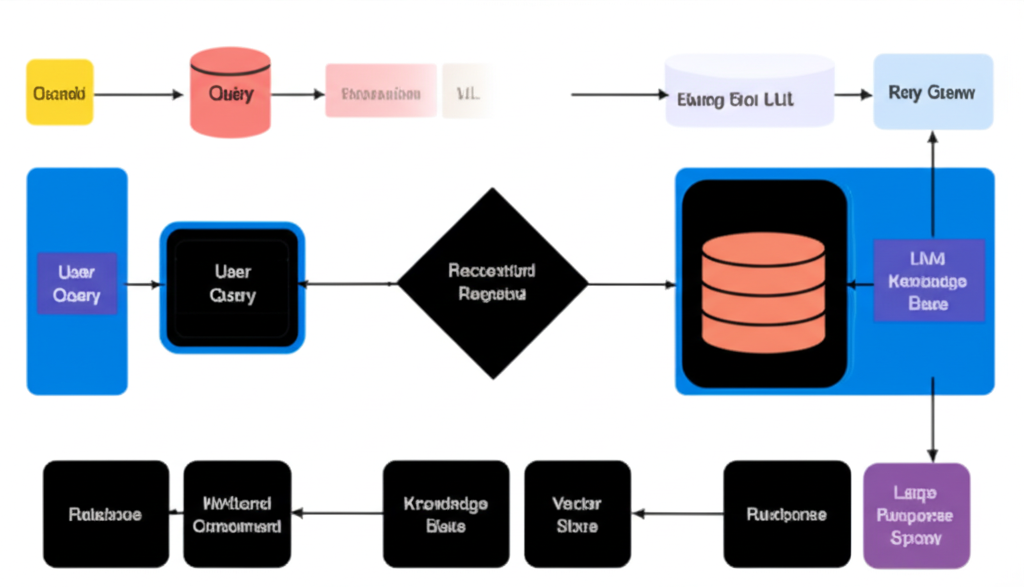
Retrieval-Augmented Generation (RAG) has become a cornerstone technology for building AI systems that can access and reason over large knowledge bases. While basic RAG implementations are well-documented, building production-ready systems requires sophisticated approaches to retrieval, ranking, and generation.
The Evolution of RAG Architecture

Traditional RAG Limitations
Basic RAG systems often struggle with:
- Retrieval Quality: Difficulty finding truly relevant documents
- Context Length: Limits when dealing with large knowledge bases
- Accuracy: Risk of hallucinations or incomplete answers
- Latency: Slow response times at enterprise scale
Advanced RAG Patterns
Modern implementations go beyond simple vector search and add layers of intelligence.
1. Hierarchical Retrieval
Instead of one-size-fits-all retrieval, advanced pipelines filter information in multiple steps — from broad document search, to paragraph-level filtering, down to sentence-level precision. This reduces noise and improves relevance.
2. Query Decomposition and Routing
Complex queries are rarely answered by a single retrieval strategy. Systems now classify queries:
- Factual → Direct lookup in knowledge base
- Analytical → Combining evidence across sources
- Temporal → Time-aware search (what was true then vs. now)
- Comparative → Side-by-side evaluation of different entities
Advanced Retrieval Techniques

Semantic Chunking
Instead of splitting documents into fixed-size blocks, semantic chunking respects natural boundaries (sections, headings, logical breaks). This ensures queries retrieve coherent pieces of information, not random fragments.
Multi-Vector Retrieval
No single embedding method is perfect. High-performing RAG systems blend:
- Dense embeddings for semantic similarity
- Sparse embeddings (e.g., BM25) for keyword matching
- Hybrid rerankers (like cross-encoders) for final scoring
Contextual Retrieval
Providing the model with metadata (like section headers, summaries, or preceding/following context) helps it interpret chunks more accurately.
Generation Enhancement Strategies

Citation and Source Tracking
Enterprise-ready RAG must be auditable. Each piece of generated output should link back to its source documents with confidence scores. This builds trust and helps identify when the system may be uncertain.
Multi-Step Reasoning
For complex queries, generation should follow a reasoning pipeline:
- Query Analysis – What’s really being asked?
- Retrieval Planning – Which sources and strategies to use?
- Evidence Gathering – Collect diverse perspectives
- Synthesis – Combine into a coherent narrative
- Verification – Check consistency and reduce hallucinations
Production Considerations

Performance Optimization
- Caching at multiple levels (embeddings, query results)
- Batch processing for similar queries
- Asynchronous pipelines for scalability
- Model optimization via quantization/distillation to reduce cost
Quality Assurance

- Automated tests for retrieval quality
- Human-in-the-loop evaluations
- Feedback loops to continuously improve retrieval accuracy
- Hallucination detection and fact-checking systems
Monitoring and Observability
Key metrics to track include:
- Retrieval precision and recall
- Response latency (P95/P99)
- User satisfaction scores
- Citation accuracy
- Infrastructure resource utilization
Advanced Use Cases

Multi-Modal RAG
Expanding beyond text-only retrieval:
- Image search for visual question answering
- Code retrieval for developer assistance
- Structured data for business intelligence
- Time series for financial and IoT forecasting
Domain-Specific Optimization
Different industries demand tailored RAG approaches:
- Legal – Case law and regulation retrieval
- Healthcare – Integrating clinical guidelines and research papers
- Finance – Supporting compliance and audit workflows
- Engineering – Navigating dense technical documentation
Future Directions

The RAG landscape continues to evolve with exciting directions:
- Agentic RAG: Systems that actively plan retrieval steps
- Multimodal RAG: Seamless integration of text, images, code, and structured data
- Real-time Learning: Adapting to new knowledge as users interact
- Federated RAG: Privacy-first retrieval across distributed knowledge bases
Conclusion
Building advanced RAG systems requires going beyond the basics. It’s not just about plugging in embeddings and a vector database — it’s about designing an end-to-end pipeline that balances accuracy, transparency, and scalability.
At The Vinci Labs, we focus on creating RAG systems that deliver not only accurate information, but also confidence, citations, and enterprise-grade performance. For organizations seeking trustworthy AI, next-generation RAG is the foundation.